1DCNN ニュウモン
系列データを扱うための 1 次元畳み込み(1DCNN)についてまとめていきたいと思います。また畳み込みに限らず、系列データを扱うための手法・モデルについても紹介します。
ライブラリ
torch.nn.Conv1d
pytorch では torch.nn.Conv1d を用いて 1DCNN を実装することと思います。パラメータは次のとおりです。
- in_channels : 入力チャンネル数
- out_channels : 出力チャンネル数
- kernel_size : 畳み込みカーネルのサイズ
- stride : カーネルの移動幅(Default: 1)
- padding : パディング(Default: 0)
- padding_mode : パディング方法 – ‘zeros’, ‘reflect’, ‘replicate’ or ‘circular’. (Default: ‘zeros’)
- dilation : カーネル内の要素の幅(Default: 1)
- groups : 入出力のチャンネルのグループを定義(Default: 1)
- bias : バイアスを入れるかどうか(Default: True)
torch.nn.GRU
Gated Recurrent Unit(GRU)は RNN の一種で、系列データを扱うために Kaggle などでも使用されています。
- input_size : 入力ベクトルの次元数
- hidden_size : 隠れ状態
hの次元数 - num_layers: 再帰層の数。(Default: 1)
- bias: バイアスを用いるかどうか(Default: True)
- batch_first: テンソルの形式について(Default: False)
- dropout: ドロップアウト層を用いるかどうか(Default: 0)
- bidirectional: 双方向にするかどうか(Default: False)
Conv1d との違いは、input_size の作り方に注意する必要があるという点かと思います。RNN 系モデルではデータは のように input_size 次元のベクトルが時間方向に並んでいるものを想定します。
例えば時間方向に 10000 のデータ点が並んでいる波形が 20 種類ある場合に、各点 20 次元のベクトルが 10000 個並んでいると考えることもできますし、波形データの時間方向をグルーピングして特徴ベクトルとすることもできると思います。ここでは前者の方法を例として擬似コードを組んでみます:
まず、8 次元ベクトルを入力とする GRU を定義します。
import torch.nn as nn
rnn = nn.GRU(input_size=8, hidden_size=128, num_layers=3, batch_first=True)バッチサイズ 16 の疑似データを作成し入力します。注意点は、通常 PyTorch で扱うテンソルはバッチサイズ、チャンネル数、データ長 (B, C, L) の順番で並んでいるのですが、このまま入力することはできない点です。GRU では
(L, B, H_{in})(batch_first = False)(B, L, H_{in})(batch_first = True)
のいずれかの形式に修正する必要があります。個人的には batch_first=True を使用したほうが混乱がなくてよいかと思います。
X = torch.randn(16, 8, 10000)
output, h_n = rnn(X.permute(0,1,2))出力はそれぞれ
output.shape # torch.Size([16, 10000, 128])
h_n # torch.Size([3, 16, 128])のようになり、最終層の出力と、隠れ層の中間出力(ここでは num_layers=3 としていたので、h_n の 1 次元目が 3 になっています)を得ることができます。
torch.nn.LSTM
基本的には nn.GRU と同じであるため、注意点は出力部分かと思います。LSTM では隠れ層の出力に加えて、cell state の出力も得ることができるため
import torch.nn as nn
rnn = nn.LSTM(input_size=8, hidden_size=128, num_layers=3, batch_first=True)
X = torch.randn(16, 8, 10000)
output, (h_n, c_n) = rnn(X.permute(0,1,2))のような出力の受け取り方になります。output だけをみると同じ次元数であるため、簡単にモデルの差し替えなどをためすことができるのが嬉しいです。
G2Net Gravitational Wave Detection
Kaggle コンペ「G2Net Gravitational Wave Detection」を参考に、1DCNN についての実装方針などをまとめます。参考にしている上位 4 つの解法では様々な手法を用いているのですが、その中でも 1DCNN の情報だけをピックアップしています。
1st solusion (コード公開無し)
前処理
- 20Hz highpass filter
モデル
モデル構造は Conv + Batch norm + SiLU ブロックを複数使用したものだそうで、以下の擬似コードようのなものを使用していたとのことです。
# Main building block for Conv1D models
class ConcatBlockConv5(nn.Module):
def __init__(self, in_ch, out_ch, k, act=nn.SiLU):
super().__init__()
self.c1 = conv_bn_silu_block(in_ch, out_ch, k, act)
self.c2 = conv_bn_silu_block(in_ch, out_ch, k * 2, act)
self.c3 = conv_bn_silu_block(in_ch, out_ch, k // 2, act)
self.c4 = conv_bn_silu_block(in_ch, out_ch, k // 4, act)
self.c5 = conv_bn_silu_block(in_ch, out_ch, k * 4, act)
self.c6 = conv_bn_silu_block(in_ch * 5 + in_ch, out_ch, 1, act)
def forward(self, x):
x = torch.cat([self.c1(x), self.c2(x), self.c3(x), self.c4(x), self.c5(x), x], dim=1)
x = self.c6(x)
return xカーネルサイズは 64 → 32 → 16 → 8 を用いています[1]。
Augmentations
- channel shuffle
- minor time shifts
その他
- AdamW ではなく SGD のほうが精度が良かった
2nd solution
モデル
この手法では wavegram を使用しています。wavegram とは PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition で導入された量で、生波形データ (N, C, L) が (N, C, T, F) の形式のスペクトログラムに変形して得られるものです。以下の処理の左側部分に該当します:
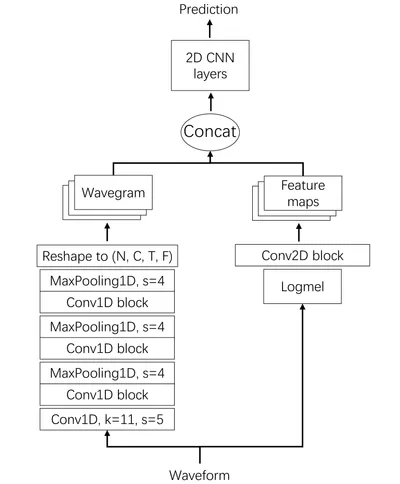
wavegram 作成のために 1DCNN (frontend) を用いるのですが、ここでは frontend CNN と呼んでいて ResNet1D-18、DenseNet1D-121、WaveNet を使用したとのことです。PANN とは異なり、
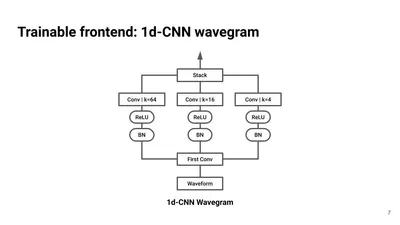
のように、frontend Conv のみを用いて解析を進めていたようです。
4th solution
モデル
初手として conv1d 8 層のみを使った実験を行いある程度の結果が出たため(LB=0.8788、50 位付近銀圏)、系列データを扱う手法を深堀りしていったようです[2]。ただ、LSTM、GRU、Transformers などを試してみたのですが、シンプルな conv1d には精度が及ばなかったとのことです。そのため、conv1d を純粋に並べて ResNet block のように舌モデルを用いて、以下のパイプラインを組んだとのことです:
- 入力データを horizontal stacking
(1, 14096*3) - bandpass filtering
- Deep Conv1D
- LSTM head
- GRU、Transformer とも比較したが LSTM が強かったとのこと
まとめ
ざっくばらんに 1DCNN について見てきましたが、Kaggle の解法などをみると大雑把には次のことが言えそうです
- カーネルサイズの調整が重要
- モデルの 1 部分の差し替え(Conv1D を XXXX にする)よりは、ブロック単位で違った思想のものを入れるのが良い
- GRU, LSTM, Transformes など
- 案外シンプルなモデルは強い
- 色々とモデリングを凝る前に、シンプルなモデルの性能を見ておくのが良いかもしれません
脚注