CV最前線: ジェスチャー動作生成
はじめに
本稿は「コンピュータービジョン最前線 Summer 2023 生成 AI」で取り上げられている記事をもとにしたものです。
ジェスチャー動作生成手法について
ジェスチャー動作生成タスクとは音声データを入力としてそれに沿ったジェスチャー動作を生成するもので、下図に示すように入力の音源(下段)から対応するジェスチャー(上段)を生成するタスクです。
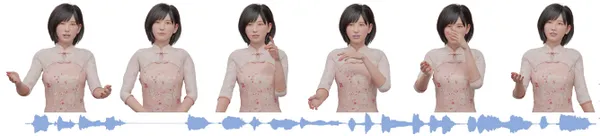
このタスクでは、音声の強弱や感情などの多様的な情報をどれだけ柔軟に上手く扱うことができるかということが重要になってきます。そのため近年では深層学習手法を用いたジェスチャー動作生成手法が発展しており、決定論的モデルと確率的生成モデルとに分類されます。ただし深層学習手法であるためどちらも広義の “確率モデル” であると言えるのですが、確率過程を陽に含んでいるかどうかで手法が分類されています。
決定論的モデル
確率的生成モデル
DisCO
多様性のあるジェスチャー動作生成に取り組んだ論文 Tan Wang et. al, 2023 から DisCo モデルを紹介します。
従来の課題
DisCo では従来手法が抱える問題として、lack of category-level annotation と inherent many-to-many mapping between motion content and rhythm を上げています。
既存のデータセットでは関節の位置や回転などの情報のみが提供されていて、motion categories (動作カテゴリー)の情報(どのような動きなのかを示す情報)が欠落しています。そのため主要なベンチマークが関節位置に関する情報をメトリクスとして使用することになり、うまく多様的なジェスチャーを評価できないという問題があり、これが “lack of category-level annotation” の問題です。
また、理想的には動作とそのリズムは無相関であるはずなのですが実際にはそうなっておらず、そのためデータセットをサンプリングするときに十分な取扱いを行わないとデータセットの情報が偏ってしまう問題があり、これが ” inherent many-to-many mapping between motion content and rhythm” の問題です。
DisCo の解決策
以上の従来手法の問題解決のために、3つの手法を提案しています。
- 学習データ分布のバランスを取り、カテゴリー情報に基づいた解析を実現する
- ジェスチャーを動作内容(content)とリズム(rhythm)に分解する
- 動作内容とリズムのマッピングを DIN で行う