学習方法について
半教師あり学習について、A Survey on Deep Semi-supervised Learning を参考にまとめます。ネットワークの学習手法について主に3つの手法があります。
- 教師あり学習 (Supervied Learning; SL)
- ラベル付きデータを用いて学習を行う手法
- 半教師あり学習 (Semi-Supervied Learning; SSL)
- 小量のラベル付きデータと、ラベル無しデータとを使用して学習を行う手法
- 自己教師あり学習 (Self-Supervied Learning; SSL)
- ラベル無しデータのみを使用して学習を行う手法
本ブログでは半教師あり学習について着目するのですが、以下の図の様に大きくわけて5つの手法があります。このうち Pseudo-labeling methods と Hybrid method についてまとめます1。
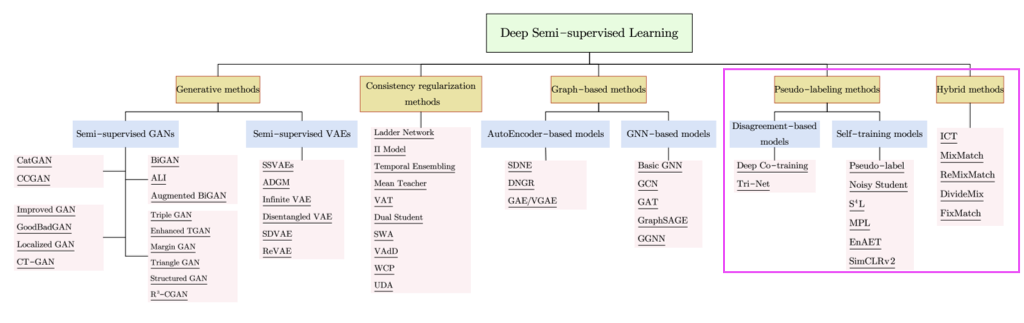
Pseudo-labeling methods
ラベル無しデータに対して pseudo label(疑似ラベル)を割り当てていく手法の総称が pseudo-labeling methods です。Pseudo labele の初出の論文では学習中のモデルの出力の信頼度が高いものが真のラベルであるとして損失を計算する手法を提案していました。これと比較して、蒸留などで用いられる手法では学習済みモデルの出力を用いてラベルを割り当てる方法が提案されています。そのため一口に「疑似ラベル」と言ってもその割り振り方法は様々に工夫のしがいがある部分であるので、どの手法を指しているかは文脈判断する必要があります。
Disagreement-based models
一つのタスクに対して複数のモデルを学習し、それらの情報を相互に使用することでラベル無しデータを扱っていく手法です。この手法の一つである、Co-training(共学習)について以下で詳しく見てきます。
具体例
RGB-D Object Recognition の2016年の論文を例に、disagreement-based models について説明していきます。 この研究ではRGB-D 情報を用いた物体検知において、半教師あり学習を用いた手法を導入することでアノテーションコストを下げつつニューラルネットワークの学習を可能としました2。
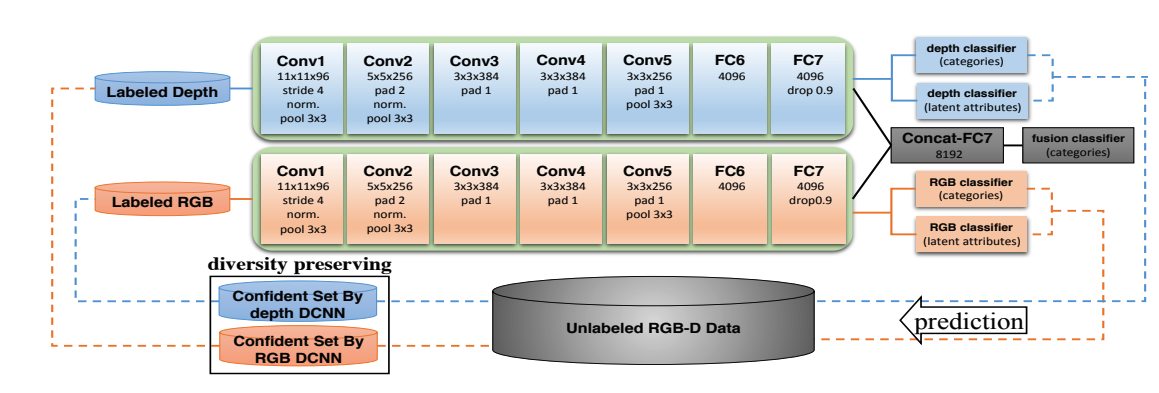
まず学習初期ではラベル付きデータを用いて、それぞれ RGB 情報のみからタスクを解くモデル(RGBモデル)、Depth情報のみからタスクを解くモデル(Depthモデル)を学習させます。ここでのタスクとは、例えば画像の物体のクラス分類などを念頭に置いています。
次にこれらのモデルを用いて、ラベル無しデータに対して pseudo labeling を行っていきます。RGB情報のみから分類した結果、Depth情報のみから分類した結果を信頼度でランキングするのですが、同じ画像に対してもそれぞれのモデルの “癖” があるために同じ出力結果にはならないことが予想できます。RGBモデルで擬似ラベルを作成したデータは次のDepthモデルの学習データに、Depthモデルで擬似ラベルを作成したデータは次のRGBモデルの学習データとします。この様にすることで、RGBモデルの不得手とする画像を効果的に学習させることができ、Depthモデルについても同様の状況になります。上図で prediction から labeled data へ移動する際に、RGBモデルの出力がDepthモデルへ、Depthモデルの出力がRGBモデルへ入力されていることに留意して見てみて下さい。
つまり Disagreement-based models の肝は、データの別の異なる特性に着目したモデルを用いることにあります。1つのモデルを用いるのではなくデータの特性にそれぞれ特化したモデルを用いることで、過学習の抑制にも繋がり汎化性能を期待できます 3。
Summary
RGB-D Object Recognition を例に Diagreement-based models を説明しました。Disagreement とは例のように、2つのモデル出力の不一致(disagreement)を利用して pseudo labeling を行っているのでそのように呼ばれます。
Self-training models (自己学習モデル)
Self-training models は、モデル自分自身の予測値を用いて疑似ラベルを割り当てていく手法です。
Enrotpy Minimization
Entropy Minimization は [Yves et. al, 2004] で提案された手法で、モデルの予測値のばらつき(entorpy)を抑える様に学習を進めます。
Pseudo Label
Pseudo-Label は [D.-H. Lee, 2013] で提案された手法で、疑似ラベルを割り当てていくという手法の初出のものです。損失関数は以下で定義されます:
$$ L = \frac{1}{n} \sum_{m=1}^n \sum_{i=1}^K R(y_i^m, f_i^m) + \alpha(t) \frac{1}{n^\prime} \sum_{m=1}^{n^\prime} \sum_{i=1}^K R({y_i^\prime}^m, {f_i^\prime}^m) $$
第一項はラベル付きデータに対する損失関数で、これは従来のクラス分類の損失関数を用いています。第二項はラベルなしデータに対する損失関数で、モデルの出力 ${f_i^\prime}^m$ のうち最も信頼度(confidence)の高いラベルを真値 ${y^\prime}^m$ として同様のクラス分類用の損失関数を計算しています4。
Noisy Student
Noisy Student は [Q. Xie et. al, 2020] で提案された手法で、基本的には知識蒸留(knowledge distillation)に沿った手法です。差異は、生徒モデル学習時に noise(データ拡張; Data Augmentation)を使用することと、教師モデルよりも大きなパラメーターを持つ生徒モデルを使用する点にあります。
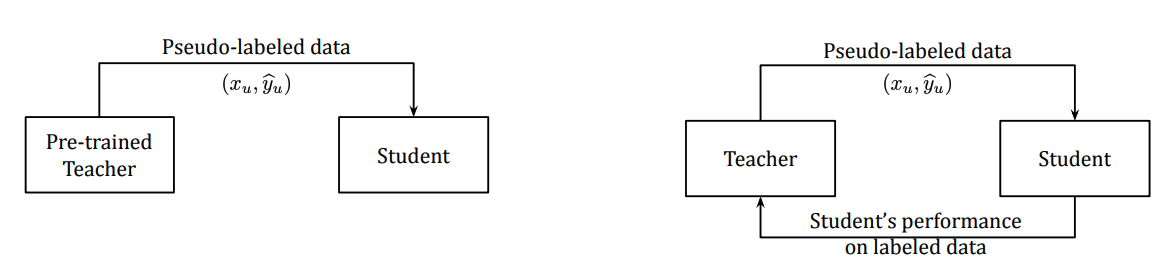
Meta Pseudo Labels (MPL)
Meta Pseudo Labels(MPL)は [H. Pham et. al, 2020] で提案された手法で、従来の知識蒸留(下図;左)の手法を更新し、生徒モデル(下図;右)からのフィードバックを教師モデルが受けるという手法です。
Hybrid Methods
pseudo-label、entropy minimization に加えて、本ブログでは紹介しなかった consistency regularization を組みあせて精度向上を図っている手法をここでは hybrid methods として紹介します。
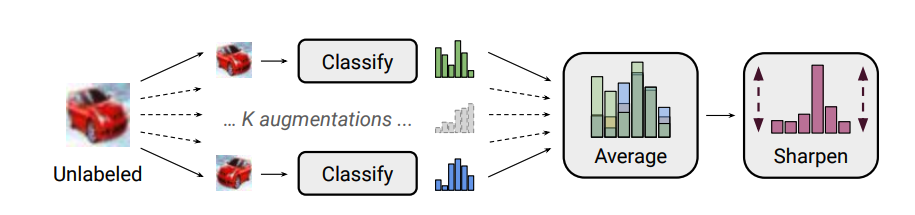
MixMatch
MixMatch は [D. Berthelot et al., 2019] で提案された手法で、ラベル無しデータに複数回 augmentation を加え、それらの平均を擬似ラベルとして割り当てます。温度パラメーターを用いて予測分布を尖鋭化することで(sharpen)、予測がより低エントロピーとなるようにしています。
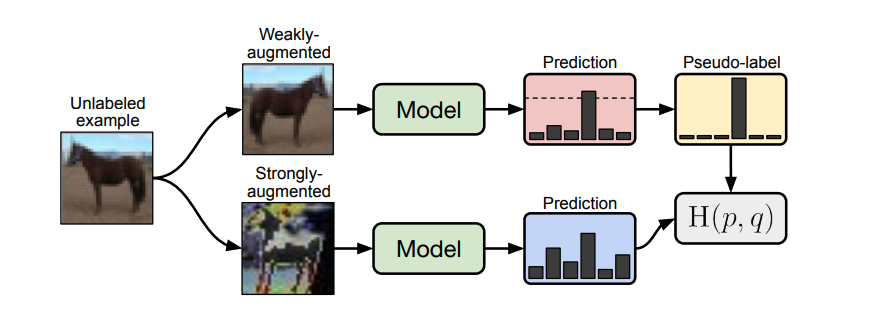
FixMatch
FixMatch は[K. Sohn et al., 2020] で提案された手法で、MixMatch の後継的な手法です。ラベル無しデータに対して弱い augmentation と強い augmentation を掛け、それらの出力の性質が変わらないように学習を進めていきます。
参考情報
- A Survey on Deep Semi-supervised Learning
- Pseudo-Label:The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
- Semi-Supervised Multimodal Deep Learning for RGB-D Object Recognition
- Semi-supervised Learning by Entropy Minimization
- 画像分類タスクにおける半教師有り学習 第1回
一口に半教師あり学習と言っても大量に手法がある(サーベイ論文では52個の手法)のだと驚きました。 ↩︎
ImageNet のような大規模データセットがないため、半教師あり学習を用いてこの問題に対処しているという背景があります。 ↩︎
参考にしている論文では “multimodal deep learning framework” と呼んでおり、最近の大規模基盤モデルで期待されるマルチモーダルについても何らかの示唆がある気がしていますが、まだまだ勉強不足です…。 ↩︎
最近では pseudo label は広義の疑似ラベル作成(基盤モデルによる作成、教師モデルによる作成 etc)という意味合いで用いられますが、元々は学習中のモデル自身が作成するという意味合いでした。 ↩︎